Investigación
Evaluación de los LLM para generación de código

Carles Gallel
Fecha de inicio
01/03/2023Estado
En progresoResumen
La investigación está centrada en aprovechar al máximo el potencial de la generación de texto de los LLM (large language models) para la generación de código. Herramientas como ChatGPT o GitHub Copilot ya utilizan LLM para ofrecer respuestas a partir del lenguaje natural introducido por el usuario. Sin embargo, la calidad de la respuesta no siempre es la esperada y, en consecuencia, el código que pueda generar no siempre será correcto. De hecho, si el código solicitado dista mucho de código con el que haya sido entrenado, es probable que no funcione como el usuario espera.
Por ello, esta investigación pretende analizar la situación actual de estos dos LLM (GPT-3/4 y Codex -el LLM que usa GitHub Copilot-) para analizar su fiabilidad a la hora de generar código. Además, como el resultado que se espera no ofrecerá las suficientes garantías para poder poner ese código en producción, se aplicarán diferentes metodologías para analizar si la salida que ofrecen es notablemente mejor, o no.
Entre las metodologías que se aplicarán, están TDD (test driven development), chain-of-though y active prompting. En función de los resultados obtenidos, se creará una extensión para el IDE Visual Studio Code para pueda ponerse a prueba.
Actualizaciones
Se han iniciado las primeras pruebas con el prototipo desarrollado y se han obtenido resultados preliminares que permiten extraer conclusiones iniciales. Como se ha mencionado en actualizaciones anteriores, el prototipo tiene la capacidad de generar automáticamente el código de una clase que representa una estructura de datos o un algoritmo. Este proceso se realiza de tres formas distintas: sin validación de código mediante tests, validando el código generado mediante una colección de tests preexistentes y validando el código con tests creados por el propio modelo de lenguaje (LLM).
Inicialmente, se podría suponer que el código más preciso es el validado mediante una colección de tests preexistentes, es decir, aquellos creadas por el propio usuario. Sin embargo, se han obtenido mejores resultados cuando es el LLM quien se encarga de crear los tests.
Además, se ha observado un comportamiento particular cuando se genera código sin validación. En concreto, se ha encontrado que la clase requerida es generada, pero todos sus métodos carecen de cuerpo y solamente incluyen la firma del método y un comentario, similar al de Javadoc. A partir de estos hallazgos, parece evidente que la validación del código generado por cualquier LLM mediante una colección de pruebas es importante.
En la siguiente gráfica se presentan los resultados obtenidos después de llevar a cabo múltiples iteraciones generando el código de una clase de una cola llamada QueueArrayImpl. En la Figura 1 se muestran los diferentes niveles de calidad alcanzados por los métodos generados. Los casos donde los métodos no tenían el cuerpo definido se identifican como "sin código" (without code), mientras que los casos donde el código generado no funcionaba correctamente debido a errores de lógica se identifican como "incorrectos" (wrong). En los casos en que el código generado era funcional pero no óptimo se identifican como "no eficiente" (not efficient). Cuando solo se encontraron pequeñas deficiencias en el código generado debido a la falta de contexto sobre las clases heredadas se identifican como "bien" (OK). Por último, los métodos generados sin ninguna deficiencia se identifican como "perfectos" (perfect).
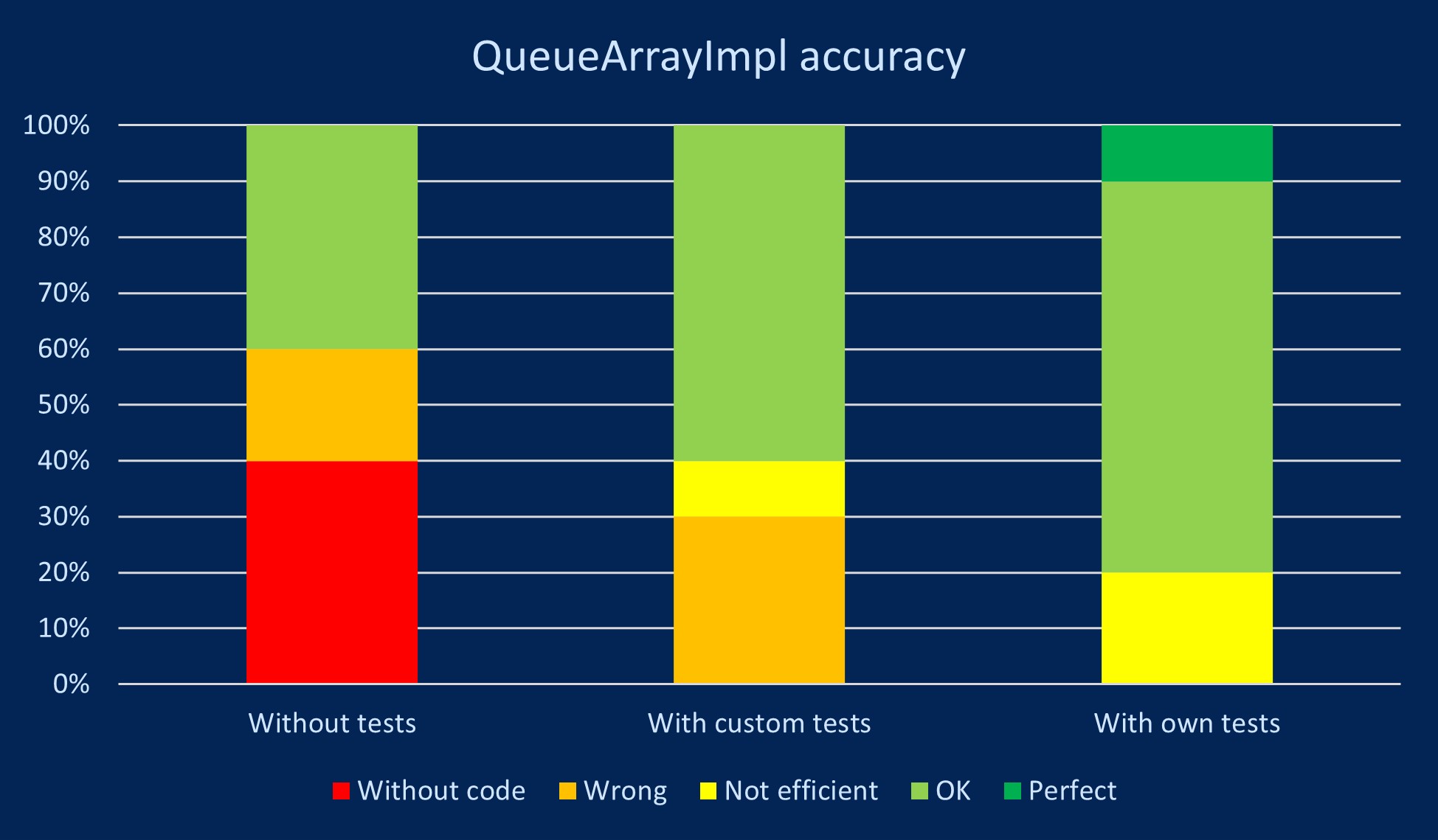
La gráfica destaca que la metodología más efectiva para generar un código correcto es aquella que incluye la creación de una colección propia de tests. Sin embargo, se ha observado en algunos casos que los tests generan falsos positivos. Esto se ha comprobado en otras clases generadas donde los métodos no tenían cuerpo y aún así, se superaban las pruebas correctamente. Esta situación es imposible, ya que las funciones no contenían código. Por lo tanto, se llega a una segunda conclusión: es crucial enviar el código y los tests a través de una API a un compilador y plataforma de ejecución para verificar si se han superado los tests correctamente. De esta manera, no se dejará la validación del código al LLM, sino que se basará en los resultados de la compilación y ejecución de la colección de tests.
A pesar de lo anterior, si se desea validar el código en un compilador real, el código generado siempre debe ser compilable y no contener errores, por mínimos que sean. Es importante destacar que en ninguna de las generaciones de código se han detectado errores de sintaxis. Por tanto, parece una idea factible y aplicable para el futuro. Esta metodología puede ser de gran utilidad en el futuro para la validación del código generado mediante la incorporación de una API que incluya la compilación y ejecución de la colección de pruebas.
Además de la calidad del código generado, es fundamental analizar los resultados en cuanto al tiempo de generación del código. Aunque los tiempos de espera sean de decenas de segundos, seguirá siendo significativamente más eficiente en términos de tiempo que si una persona generara el código. Sin embargo, es necesario hacer una comparativa entre las distintas metodologías aplicadas para determinar si la tercera metodología, que genera la colección de pruebas, sigue siendo la mejor.
Dejando el apartado de la calidad del código generado, también es importante mostrar resultados acerca del tiempo de generación del código. Si bien es cierto que, aunque se obtengan tiempos de espera de la magnitud de decenas de segundos, seguirá siendo mucho más eficientemente temporalmente que una persona, hay que hacer una comparativa entre las diferentes metodologías aplicadas para validar, o no, si la mejor metodología sigue siendo la tercera, la que genera la colección de tests.
La Figura 2 ilustra el tiempo de espera correspondiente a cada generación de código en segundos.
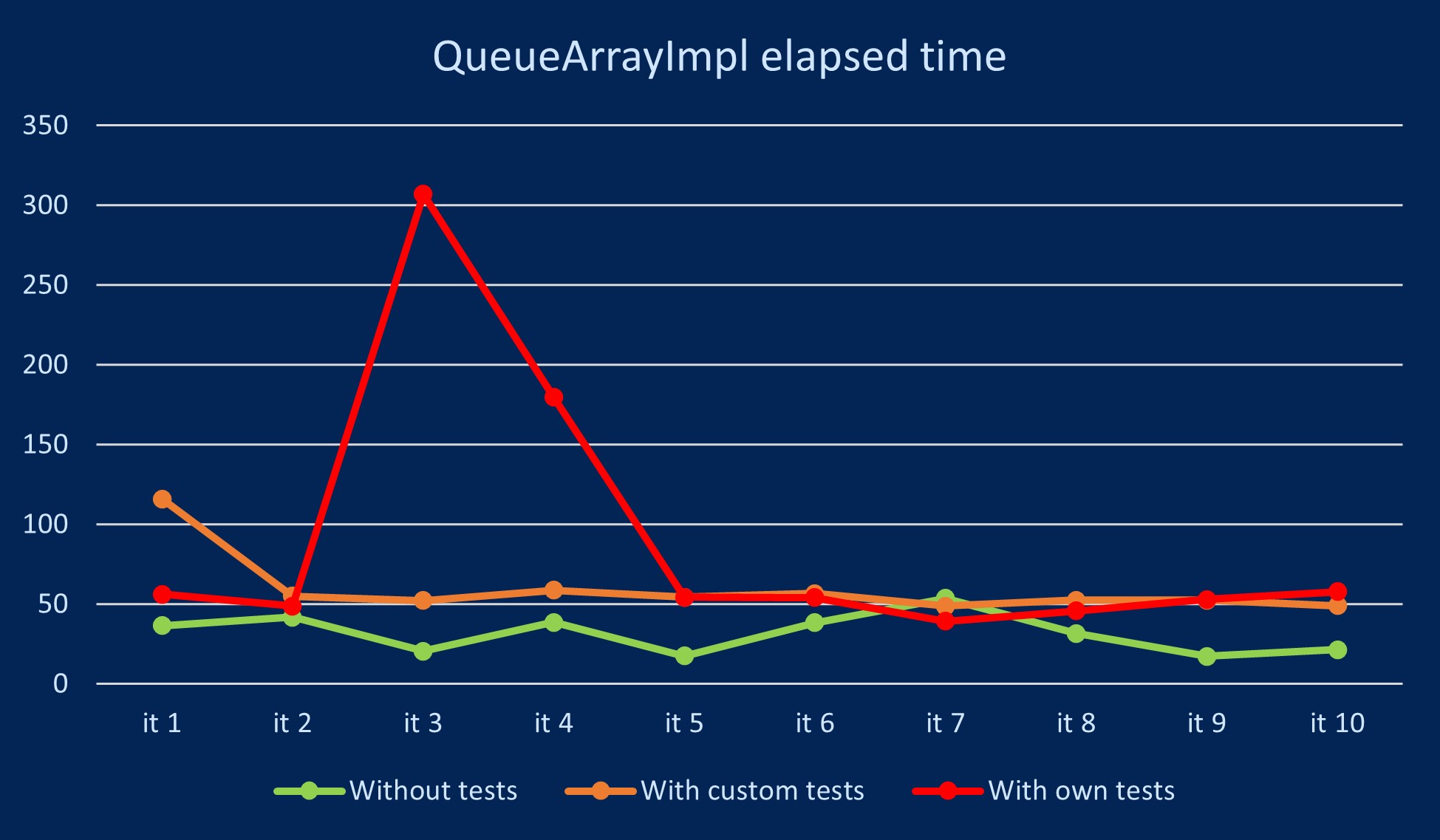
La gráfica anterior muestra los resultados que se esperaban inicialmente, ya que la metodología que menos tarda es la que no debe validar el código generado mediante una colección de tests. Sin embargo, se observan distintos outliers, especialmente, con la metodología que genera los tests. Por lo tanto, este es un aspecto a tener en cuenta, ya que, dependiendo de la carga que tenga el LLM en un momento en concreto, los tiempos de espera pueden ser considerablemente más largos de lo habitual. En cualquier caso, se puede afirmar que, dejando de lado los valores atípicos de la gráfica, las metodologías que validan el código con una colección de tests suelen tener tiempos de espera similares entre ellos.
Finalmente, cabe destacar que estos resultados son una primera aproximación. En futuras actualizaciones se proporcionarán muchos más datos que permitirán obtener gráficas más precisas y representativas de lo que sucede en la mayoría de los casos. Es decir, los datos presentados en estas gráficas pueden verse afectados por ciertos sesgos según el tipo de código que se deba generar y el momento en que se hayan ejecutado las pruebas.
Después de varios días, ya se ha conseguido tener un prototipo funcional que permite generar código usando la API de OpenAI aplicando distintas metodologías. Concretamente, como el primer prototipo tiene como objetivo evaluar la calidad y precisión del código generado, este se ha automatizado para que sea capaz de leer la documentación javadoc de un proyecto ya existente e intente generar el código a partir de la firma de la clase, los constructores y los métodos junto a su descripción. Toda esta información es tratada y se envía a la API de OpenAI como si de texto natural se tratara, intentando simular la interacción que podría tener un usuario cualquiera con el LLM.
Antes, pero, como se comentó en la actualización anterior, es muy importante especificar el rol que tiene que adoptar el LLM. Además, especificando que es un generador de código y que siempre debe devolver el código generado dentro de etiquetas XML, se puede controlar la respuesta de una manera mucho más sencilla. Asimismo, también es posible especificar si debe seguir ciertos patrones antes de devolver la respuesta. Ahí justamente es donde entra en juego la posibilidad de aplicar diferentes metodologías y ver la calidad del código con cada una.
- La primera generación de código que se evaluará es a partir de lenguaje natural obtenido de la documentación javadoc sin aplicar ningún comportamiento específico más allá del rol que debe asumir el LLM.
- La segunda, será a partir del mismo texto, pero especificando que debe validar el código generado a partir de una colección de tests que se proporcionarán. Como el proyecto utilizado ya tiene esa colección de tests, se proporcionará el documento Java que los contiene.
- La tercera generación de código también tendrá que validar el código que haya generado, pero se especificará que los tests los debe crear por sí mismo en función de la entrada que haya recibido. Es decir, si en la entrada se pide que debe crear una clase que represente una lista enlazada, deberá crear los tests necesarios para validar el código generado.
Una vez generado el código, será importante evaluarlos uno a uno para poder comparar el código generado con el original. No obstante, durante la realización de las pruebas ya se han encontrado algunos problemas que se citarán a continuación.
- Algunas clases implementan ciertas interficies o heredan otras clases. Como el LLM no dispone de esta información, el código que genera incluye partes de las clases padre y dista considerablemente del código original. Por lo tanto, el primer problema que parece evidente es la falta de contexto a la hora de generar código. Como solución a ello, se modificará el prototipo para que se proporcione dicho contexto de forma recursiva hasta llegar a la clase Object. Asimismo, con el objetivo de acortar la cantidad de tokens a enviar, solo se pasará el contenido completo de la clase padre directa. Para las demás clases que no sean padre directo de la clase que se quiere generar, solo se proporcionarán sus atributos y sus métodos. No obstante, habrá que ver si esto es posible a corto plazo, ya que existe una limitación de tokens a la hora enviar texto a la API.
- Algunas veces el código generado no contiene algunas partes importantes. En ciertas ocasiones, la respuesta que proporciona no contiene la declaración de los atributos. Para dar solución a este problema se ha modificado el texto que recibe inicialmente y se le ha especificado que debe generar los atributos necesarios para que el código funcione correctamente. Además, ha habido algunas situaciones en las que el código generado solo contenía la firma de los métodos con un comentario dentro, sin proporcionar el cuerpo. Este problema no es muy habitual y, por ahora, no se ha dado solución a ello. Se está a la espera de que vuelva a pasar con el contexto modificado.
- La disponibilidad de la API de OpenAI, a pesar de tener una cuenta plus no siempre es la deseada. Por ello, muchas veces el prototipo no es capaz de generar el código, ya que la API no es capaz de proporcionar esta respuesta. Dicho problema está fuera del alcance de esta investigación porque se está trabajando con la API de un tercero, así que por ahora no se puede dar solución a ello.
- Los recientes anuncios del Parlamento Europeo y el Gobierno Español ponen en riesgo la investigación y, en general, el uso de la API de GPT. De hecho, el Gobierno Italiano ya adoptó medidas y ha bloqueado en su totalidad el uso de ChatGPT y, en consecuencia, la API de GPT que usa el prototipo utilizado. A pesar de que el Parlamento Europeo ha dado un plazo de dos meses para resolver la disputa, en caso de que decidan cerrar el servicio en la Unión Europea, la investigación seguirá utilizando servidores de Estados Unidos o de otro país donde no esté bloqueado el servicio.
Con todo el código generado, es momento de analizar si con las metodologías aplicadas el código generado es lo suficientemente correcto, si el tiempo de espera es aceptable o si es necesario cambiar de estrategia y aplicar otras técnicas. En cualquier caso, una vez analizado, ya se tiene previsto hacer ciertas modificaciones y aplicar técnicas como las que se describirán a continuación.
- Generar el código creando una cadena conversacional con el LLM.
- Proporcionar ejemplos de código como el que debe generar.
- Modificar la temperature para evaluar su comportamiento.
- Validación del código compilándolo con un compilador real y que no sea el mismo LLM que deba validarlo.
Se ha finalizado la primera versión del prototipo que permite generar código a partir de lenguaje natural con ChatGPT utilizando la biblioteca langchain. Después del desarrollo de este, se han observado ciertos aspectos muy interesantes a destacar.
- Es posible especificar cómo debe devolver el texto generado y, en consecuencia, el código. Gracias a esto, se ha creado el prototipo orientado al lenguaje XML, donde exista una etiqueta code con el código generado y, después, varias etiquetas con los tests que se hayan generado con su resultado. De esta manera, es mucho más simple tratar los datos por el prototipo.
- Es muy importante indicarle qué tipo de rol debe asumir el LLM. Es decir, para nuestro caso, el LLM debe comportarse como un generador de código y validador de este mediante los tests. Si se le especifica claramente, la respuesta que da se acerca mucho más a la esperada y se evita texto innecesario que suele crear ChatGPT (innecesario para este caso, no que no sirva para ninguna situación).
- Hay que tener mucho cuidado con la limitación de caracteres en la respuesta de ChatGPT, ya que corta el código cuando llega al límite y no lo completa debidamente. Se debe dar solución a este problema para poder generar varias funciones a la vez o clases completas.
Hasta ahora se ha creado para ChatGPT debido a que se quieren iniciar las pruebas cuando antes mejor por el riesgo de un posible cierre temporal. Ya existe un precedente, en Italia, y puede poner en riesgo toda la investigación.
Después de hacer un estudio del estado del arte de los LLM y, concretamente, de los que se pretende estudiar, se ha concluido que el prototipo se va a desarrollar con Python debido a su velocidad, porqué tiene una comunidad muy amplia enfocada a usar el lenguaje con este tipo de modelos y por el tener compatibilidad con la biblioteca langchain, que permite enviar peticiones a las API de estos LLM de una manera muy simple.
Si finalmente el estudio lo permite, se va a crear una extensión para Visual Studio Code, pero como esta tiene que estar hecha en JavaScript y el prototipo estará creado en Python, se creará una API del prototipo para poder mandar y recibir mensajes actuando como si de una caja negra se tratara.
Finalmente, debido al abrupto cierre de la API de Codex, se utilizará la API de davinci.